Een van de grootste obstakels bij de adoptie van kunstmatige intelligentie is dat het niet kan verklaren waarop een voorspelling is gebaseerd. Deze machine learning-systemen zijn zogeheten black boxes wanneer ze beslissingen nemen waarvan de onderliggende redenering voor de gebruiker niet begrijpelijk zijn. Meike Nauta, promovenda bij de vakgroep Data Science binnen de faculteit EEMCS van de Universiteit Twente, heeft een model gemaakt om het blackbox-karakter van deep learning-modellen aan te pakken.
Algoritmes zijn al in staat om nauwkeurige voorspellingen te doen, zoals medische diagnoses, maar ze kunnen niet verklaren hoe ze tot een dergelijke voorspelling zijn gekomen. De afgelopen jaren is er veel aandacht geweest voor het uitlegbare AI-veld. “Voor veel toepassingen is het belangrijk om te weten of het model de juiste redenering gebruikt om tot een bepaalde voorspelling te komen. Met verklaarbare AI kunnen vragen als ‘wat heeft het model geleerd?’ en ‘hoe komt het model tot zo’n voorspelling?’ worden beantwoord”, zegt Nauta.
Eerder uitlegbaar AI-onderzoek maakte veelal gebruik van post-hoc verklaarbaarheidsmethoden, waarbij het model pas na training van het model wordt geïnterpreteerd. Een relatief nieuwe richting, waar nog weinig onderzoek naar is gedaan, is ‘intrinsically interpretable machine learning'. Het grote verschil hierin is dat de uitlegbaarheid al in het model zelf is verwerkt: interpretability by design. Hier is Nauta mee aan de slag gegaan - en met succes! Ze ontwikkelde een model genaamd Neural Prototype Tree, kortweg ProtoTree, voor interpreteerbare beeldclassificatie. Dit onderzoek draagt bij aan het nieuwe, veelgevraagde veld van intrinsically interpretable machine learning, dat zowel verklaarbaar is als naar waarheid zijn eigen redenering weergeeft.
Hoe werkt het?
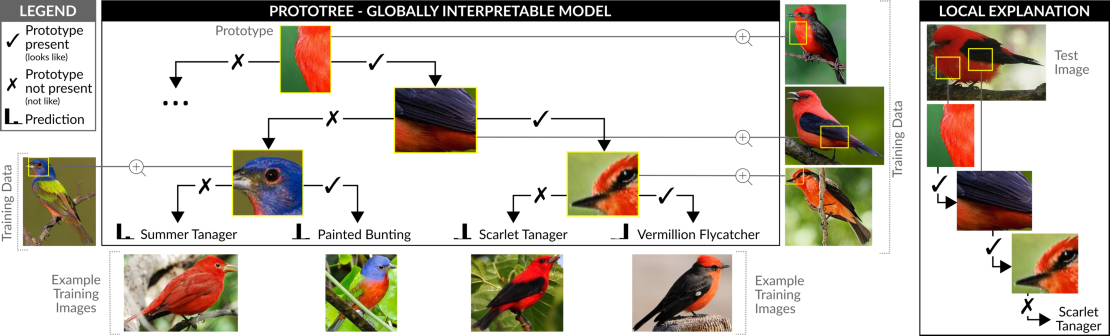
“De redenering van het model is vergelijkbaar met het spel ‘Wie ben ik?’, waarbij je bijvoorbeeld vraagt of de persoon rood haar heeft. Je krijgt een ja of nee antwoord, waarna je de volgende vraag stelt”, zegt Nauta. Het ProtoTree-model werkt volgens hetzelfde principe. Het model is getraind op een dataset bestaande uit afbeeldingen van 200 verschillende vogelsoorten. Wanneer het model wordt blootgesteld aan een input image, zoekt het model naar overeenkomende fysieke kenmerken van een soort vogel - bijvoorbeeld bij de aanwezigheid van een rode borst, een zwarte vleugel en een zwarte streep bij het oog, wordt een Rode Tiran herkent.
Volgens Christin Seifert, hoogleraar aan de Universiteit van Duisburg-Essen in Duitsland en co-auteur van de paper, is dit proces vergelijkbaar met het aanleren van nieuwe dingen aan een kind. “Je vertelt een kind bijvoorbeeld dat het dier op de foto een hond is, maar je vertelt het kind niet precies welke fysieke eigenschappen een hond heeft. Het kind leert simpelweg andere honden herkennen aan de hand van die ene foto van een hond”, aldus Seifert.
Voordelen
“Een van de grootste voordelen is dat het model stapsgewijs kan redeneren, waardoor je kunt volgen hoe het model tot een bepaalde voorspelling komt”, zegt Nauta. “Bovendien laat het ook zien waar het model zijn keuzes precies op heeft gebaseerd, zodat verkeerd geleerde associaties in het model kunnen worden ontdekt”. ProtoTree onthulde bijvoorbeeld de vooringenomenheid dat het model leerde om een type watervogel te onderscheiden van een zangvogel door te kijken naar de aanwezigheid van boombladeren. Door de mogelijke vooroordelen van het model te laten zien, is discriminatie door machine learning-algoritmen aangepakt.
Wat is hier nieuw aan?
De aanpak levert een beslisboom op, wat niet nieuw is – beslisboom-learning bestaat al tientallen jaren. Echter worden beslisbomen zelden gebruikt voor beeldclassificatie omdat standaard beslisbomen niet goed met afbeeldingen kunnen omgaan. “De nieuwigheid hier is dat de beslispunten bestaan uit kleine afbeeldingen die in één oogopslag geïnterpreteerd kunnen worden en dus betekenisvol zijn voor de mens. Deze zogeheten ‘prototypes’ zijn bovendien automatisch ontdekt uit alleen de voorbeeldbeeldgegevens”, zegt Maurice van Keulen, Universitair Hoofddocent binnen de faculteit EEMCS van de Universiteit Twente. Het magische hieraan is dat er in dit proces geen menselijk deskundig begrip nodig is, alleen enkele voorbeeldafbeeldingen. Van Keulen: "Stel je voor: je weet niets van vogelsoorten, je krijgt allemaal foto's van vogels met de bijbehorende namen, waarna jij vervolgens een boek moet gaan schrijven over het categoriseren van vogels."
Ter vergelijking: bij black box machine learning is de computer een leerling die leert een taak zelf uit te voeren. Het leert dus vogels te classificeren door de naam van de vogel te 'voorspellen'. Bij intrinsically interpretable machine learning wordt de computer echter een leraar die mensen kan onderwijzen, zonder dat deze zelf enige opleiding heeft genoten.
Motivatie voor toekomstig onderzoek
Het model is tot nu toe alleen toegepast op standaard benchmarks met auto's en vogels, maar in toekomstig onderzoek zou Nauta het model graag toepassen in andere belangrijke domeinen. “De gezondheidszorg zou een interessante sector zijn om nader onderzoek te doen naar de toepasbaarheid van het ProtoTree-model, bijvoorbeeld het herkennen van breuken op röntgenfoto’s”, zegt Nauta. “Het begrijpen van de redenering van het model is enorm belangrijk - wanneer een arts een behandelmethode of diagnose vanuit AI krijgt, moeten artsen zelf in staat zijn om dit te begrijpen en de redenering te kunnen valideren. Omdat het ProtoTree-model dit kan, zou het interessant zijn om onderzoek te doen naar de toepasbaarheid in de medische sector. Daarom werken we momenteel toe naar samenwerking tussen de University of Twente, ZGT (Ziekenhuisgroep Twente), het Institute for AI in Medicine in Essen en de Universiteit van Münster.”
Belangrijke erkenning
Onlangs heeft Nauta aanzienlijke erkenning gekregen voor haar werk. Haar paper is geaccepteerd op de CVPR2021 - de jaarlijkse conferentie over computervisie en patroonherkenning. Het is de belangrijkste conferentie in zijn vakgebied en staat op de 5e plek in de lijst belangrijkste publicaties (onafhankelijk van het domein). De editie van dit jaar vindt plaats van 19 t/m 25 juni en zal vanwege COVID-19 volledig virtueel zijn.
Nauta's paper is gepubliceerd via Computer Vision Foundation, een non-profitorganisatie die alle CVPR-publicaties open-access beschikbaar stelt. Je kunt de paper lezen op de website van CVPR.
ICT.OPEN2021
Maar dat is niet de eerste keer dat Nauta erkenning krijgt voor haar werk: afgelopen februari won ze de eerste prijs in de posterwedstrijd op de Nationale ICT Research conferentie ICT.OPEN2021. De poster is hier te vinden.




