Master Assignment
semi-supervised deep learning for point cloud classification
Student project on bat sound analysis
Type: Master EE/CS
Practical information
- Student profile: HBO-ICT, Applied Computer Science, MSc computer science, graduate student. The student must have basic knowledge of Data science as well deep learning. Experience with TensorFlow/ Pytorch is a plus.
- Period: Feb 2021 - July 2021
- (Possible) Compensation: 230 euro per month (before taxes) when carrying out this assignment at Ambient Intelligence (as internship or graduation project).
- More information: saxion.nl/ami
Student: (Unassigned)
If you are interested please contact :

Description:
Digitalization of rail-road infrastructure is aimed at the improvement of maintenance and construction activities. Currently, inspections are done manually, with a domain expert classifying objects. 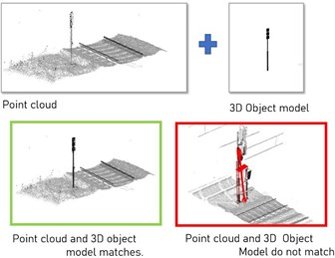
Strukton Rail works with point clouds, which are sets of spatial data points captured by 3D scanning techniques such as lidar. These point clouds contain many million points of data, resulting in 3D representations of the railway environment. Point cloud data can be used to create machine learning models that can classify the object in rail infrastructure automatically. One hurdle is the reliance on labeled data set to train such models. Since the data is labeled manually, which is an error-prone process, secondly, it requires a great deal of effort to label data.
Objective:
In this project, the aim is to use semi-supervised learning in a deep learning context to deal with sparsely labeled data and create classification models that can classify railroad objects to a certain degree of accuracy. More concretely, in this project, the student will
- Prepare a state of the art for semi-supervised learning in the deep learning perspective. The focus shall be on point cloud classification using semi-supervised learning based deep learning [ start from e.g. 1,2].
- Training of semi-supervised learning-based model for point cloud classification on Delfts point cloud data set.
- Creation of estimates on the percentage of labels required for creating a usable classification model.
- Integration of model into a dashboard for visualization of results.