Generatieve AI kan compleet nieuwe afbeeldingen maken op basis van een omschrijving. Deze modellen werken het best wanneer ze afbeeldingen van losse objecten genereren. Het maken van een complete, kloppende scène is vaak nog te moeilijk. Michael Ying Yang, een UT-onderzoeker van de faculteit ITC ontwikkelde onlangs een nieuwe manier om de relaties tussen objecten afbeeldingen in een graaf te zetten. Die grafen kan je weer gebruiken om realistische en samenhangende afbeeldingen te maken. De onderzoeker publiceerde zijn model onlangs in het wetenschappelijke tijdschrift IEEE T-PAMI.
Mensen kunnen uitstekend de relaties tussen objecten definiëren. "Wij zien dat een stoel op de grond staat en dat er een hond op straat loopt. AI-modellen vinden dit moeilijk", vertelt Michael Ying Yang, assistent-professor bij de Scene Understanding Group van de faculteit Geo-Information Science and Earth Observation (ITC). Door computers beter te maken in het detecteren en begrijpen van visuele relaties wordt het makkelijker om afbeeldingen te genereren. Maar het kan ook verbeteren hoe autonome voertuigen en robots dingen kunnen zien.
Van twee stappen naar een stap
Er bestonden al manieren om de verschillende semantische relaties in een afbeelding in grafen te stoppen, maar deze zijn te traag. Deze modellen gebruiken een tweefasenaanpak. Eerst brengen ze alle objecten in afbeelding in kaart. In de tweede stap doorloopt een specifiek neuraal netwerk alle mogelijke verbindingen en labelt deze vervolgens met de juiste relatie. Het aantal verbindingen dat deze methode moet doorlopen neemt exponentieel toe met het aantal objecten. "Onze modellen nemen slechts één stap. Het voorspelt automatisch en tegelijkertijd onderwerpen, objecten en hun relaties", zegt Yang.
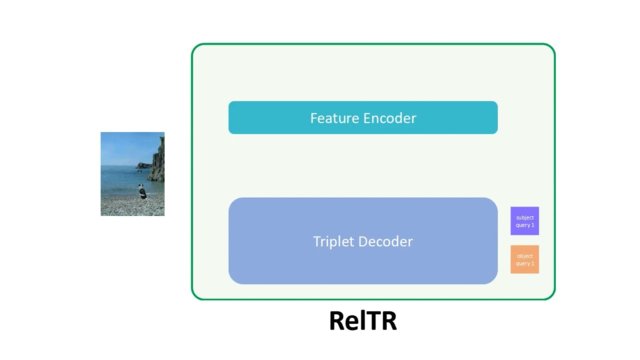
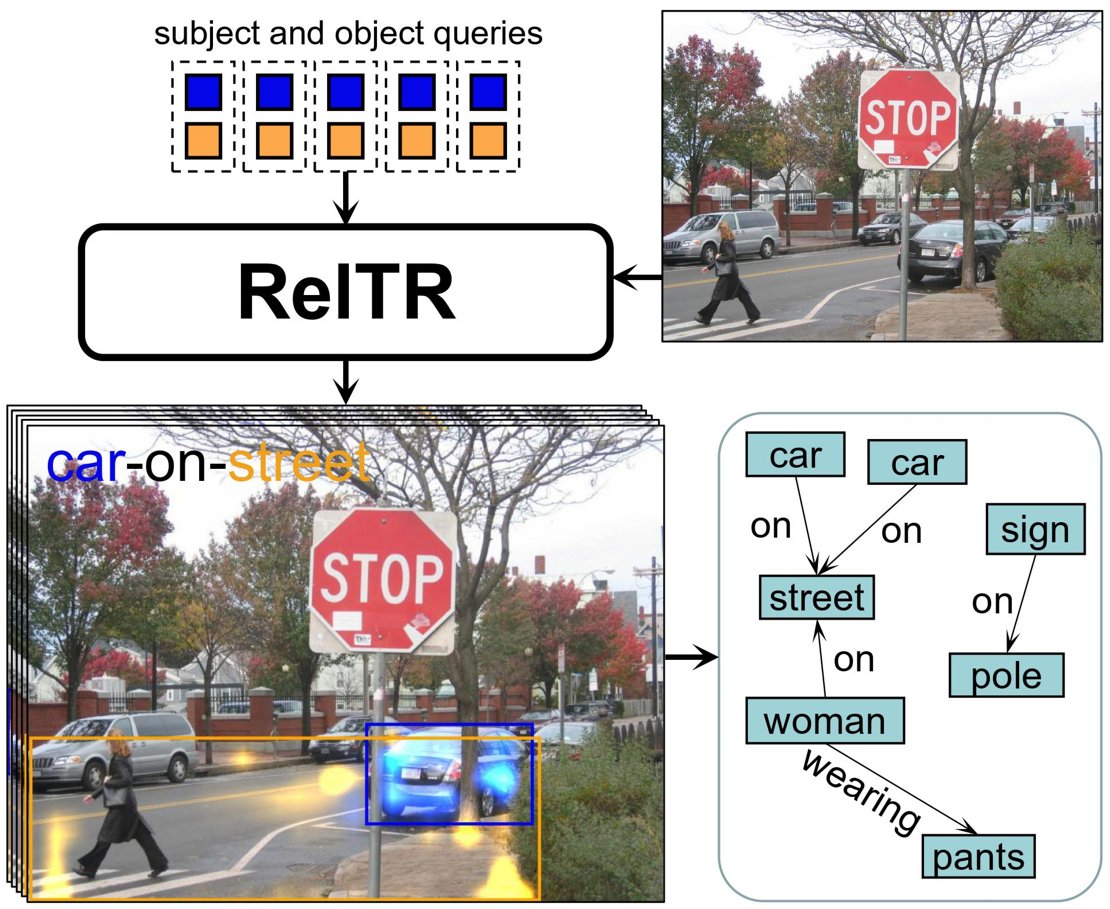
Relaties detecteren
Voor deze eenstapsmethode kijkt het model naar de visuele kenmerken van de objecten en richt het zich op de meest relevante details voor het bepalen van de relaties. Het markeert belangrijke gebieden waar objecten interactie met elkaar hebben. Deze technieken en relatief weinig trainingsdata zijn voldoende om de belangrijkste relaties tussen verschillende objecten te identificeren. Het enige wat nog gedaan moet worden is een beschrijving genereren van hoe ze met elkaar verbonden zijn. "Het model detecteert dat in een voorbeeldfoto de interactie tussen de man en de honkbalknuppel zeer waarschijnlijk is. Vervolgens trainen we het model om de meest waarschijnlijke relatie te beschrijven: 'man-zwaait-honkbalknuppel'", zegt Yang,
Meer informatie
Dr. Michael Ying Yang is assistent-professor aan de afdeling Earth Observation Science. Zijn onderzoek richt zich op computervisie met een specialisatie in het begrijpen van scènes. Samen met onderzoekers van de Leibniz Universiteit Hannover publiceerde hij zijn bevindingen in een artikel, getiteld 'ReITR: Relation Transformer for Scene Graph Generation', in het wetenschappelijke tijdschrift IEEE Transactions on Pattern Analysis and Machine Learning.




