2 Methode slachtofferstudie
2.1 Steekproef
Van 11 januari tot 2 februari 2021 is een vragenlijst afgenomen via het LISS-panel (Longitudinal Internet Studies for the Social Sciences-panel, CentERdata (2021)). Het LISS-panel is een online panel dat bestaat uit circa 5000 Nederlandse huishoudens, grofweg 7500 individuen, en wordt beheerd door CentERdata (verwant aan Tilburg University). Deelnemende huishoudens zijn door middel van een aselecte steekproef geworven uit het bevolkingsregister van het Centraal Bureau voor Statistiek; als huishoudens niet over een computer en/of internetverbinding beschikken, kunnen ze dit ontvangen om toch deel te nemen (CentERdata, 2021). Deze werving levert goede representativiteit voor de Nederlandse bevolking op (Brüggen, Brakel, & Krosnick, 2016; De Vos, 2010; Eckman, 2016; Scherpenzeel, 2018).
LISS-panelleden nemen allen deel aan de ‘LISS Core Study.’ Dit is een uitgebreide longitudinale studie die jaarlijks wordt herhaald en het mogelijk maakt om veranderingen in de levensloop en levensomstandigheden van de panelleden te volgen. Onder andere gemeten wordt de gezondheid, politieke standpunten, religie, etniciteit, sociale integratie, vrijetijdsbesteding, gezinssituatie, inkomenssituatie en persoonlijkheidskenmerken van panelleden (CentERdata, 2021). Al deze achtergronddata is beschikbaar wanneer een vragenlijst wordt afgenomen via het LISS-panel. Daarom bevat de vragenlijst van het huidige onderzoek enkel vragen gericht op fraude.
3623 willekeurig geselecteerde LISS-panelleden zijn uitgenodigd voor deelname aan de vragenlijst, waarvan 2920 de vragenlijst startten. Na selectie op compleet ingevulde vragenlijsten resteerden hiervan 2873 respondenten. Verwijdering van 9 respondenten die onbetrouwbare antwoorden gaven leidde tot een behaalde steekproef van 2864 respondenten (zie 2.3).
Hoewel het LISS-panel een goede afspiegeling van de samenleving is, bestaan er verschillen bestaan tussen de demografie van de uitgenodigde leden van het LISS-panel en de Nederlandse bevolking. Sommige demografische groepen reageren daarnaast vaker op de uitnodiging dan anderen. Bij aselecte steekproeven, zoals die van het LISS-panel, kan het wegen van data dan uitkomst bieden om onderzoeksresultaten representatiever te maken voor de doelpopulatie (Yeager et al., 2011). Via iteratieve post-stratificatie met de rake-functie van het ‘survey’ R-pakket (Lumley, 2020) is de behaalde steekproef gewogen naar frequenties van geslacht, leeftijd en opleidingsniveau. Tabel 2.1 toont de hiervoor gebruikte categorieën en bijbehorende frequenties, voor de uitgenodigde, behaalde en gewogen steekproef en de Nederlandse bevolking op 1 januari 2020.
% (N) Uitgenodigde steekproef |
% (N) Behaalde steekproef |
% Gewogen steekproef |
% Nederlandse bevolking |
|
| 100 (3623) | 100 (2864) | 100 | 100 | |
| Geslacht (16+) | ||||
| Man | 45.0 (1630) | 44.9 (1285) | 49.2 | 49.4 |
| Vrouw | 55.0 (1993) | 55.1 (1579) | 50.8 | 50.6 |
| Leeftijd | ||||
| 16 - 24 | 10.5 (382) | 8.3 (238) | 13.5 | 13.4 |
| 25 - 34 | 15.8 (571) | 13.1 (375) | 15.2 | 15.4 |
| 35 - 44 | 14 (508) | 12.1 (347) | 14.2 | 14.3 |
| 45 - 54 | 15.3 (556) | 15.4 (442) | 17 | 17.0 |
| 55 - 64 | 17 (616) | 18.8 (538) | 16.3 | 16.3 |
| >= 65 | 27.3 (990) | 32.3 (924) | 23.7 | 23.6 |
| Opleidingsniveau (15+) | ||||
| Basisonderwijs | 7.9 (288) | 7.3 (209) | 9.6 | 9.6 |
| Vmbo, mbo 1, avo onderbouw | 17.7 (643) | 19.0 (545) | 20.3 | 20.3 |
| Havo/vwo | 10.7 (386) | 10.4 (299) | 9.8 | 9.8 |
| Mbo 2, 3, 4 | 23.2 (842) | 23.1 (661) | 27.5 | 27.5 |
| Hbo | 26.6 (964) |
26.9 (771) |
20.8 |
20.8 |
| Wo | 13.8 (500) | 13.2 (379) | 12.0 | 12.0 |
1: Cijfers voor de Nederlandse bevolking per 1 januari 2020 zijn samengesteld door CentERdata, op basis van CBS Statline. CentERdata noteert: “CBS gegevens voor opleiding zijn gebaseerd op een steekproef van personen van 15 jaar of ouder.”
2: 17 LISS-panelleden in de uitgenodigde steekproef, waarvan 14 in de behaalde steekproef, hebben geen opleiding gevolgd. Deze zijn, om wegen mogelijk te maken zonder CBS-cijfers over de grootte van deze groep, onder het opleidingsniveau ‘basisonderwijs’ geplaatst.
Een vergelijking van de (ongewogen) behaalde steekproef met de verdeling binnen de Nederlandse bevolking laat zien dat er iets te weinig mannen (-4.5%) waren. Ook was de jongste leeftijdsgroep (16 - 24) ondervertegenwoordigd (-5.1%) en de ouderen (65 en ouder) oververtegenwoordigd (+8.6%). Tenslotte waren personen met hbo-opleiding oververtegenwoordigd (+6.1%) terwijl personen met een mbo-opleiding ondervertegenwoordigd waren (-4.4%). Na de weging zijn al deze verschillen afgenomen tot 0.2% of minder.
2.2 Vragenlijst
2.2.1 Fraudetaxonomie
De afgenomen vragenlijst is gebaseerd op de door DeLiema, Mottola, & Deevy (2017) ontwikkelde fraudevictimisatievragenlijst. Deze in de Verenigde Staten afgenomen vragenlijst paste het framework voor fraudeclassificatie van het Stanford Center on Longetivity toe, en mat de zeven hoofdcategorieën van fraude: 1) investeringsfraude, 2) aankoopfraude (aankoopfraude), 3) baanfraude, 4) prijsfraude, 5), schuldfraude, 6) goede-doelenfraude en 7) relatiefraude.
De huidige vragenlijst breidde deze taxonomie uit. Relatiefraude is opgesplitst in vriend-in-nood-fraude en datingfraude. De fraudevormen identiteitsfraude (gebaseerd op de Veiligheidsmonitor (CBS, 2020)), phishing (gebaseerd op 2020) en spoofing zijn daarnaast toegevoegd.
Figuur 2.1 toont schematisch de toegepaste fraudetaxonomie (de vragen vormen de definities van de fraudecategorieën).
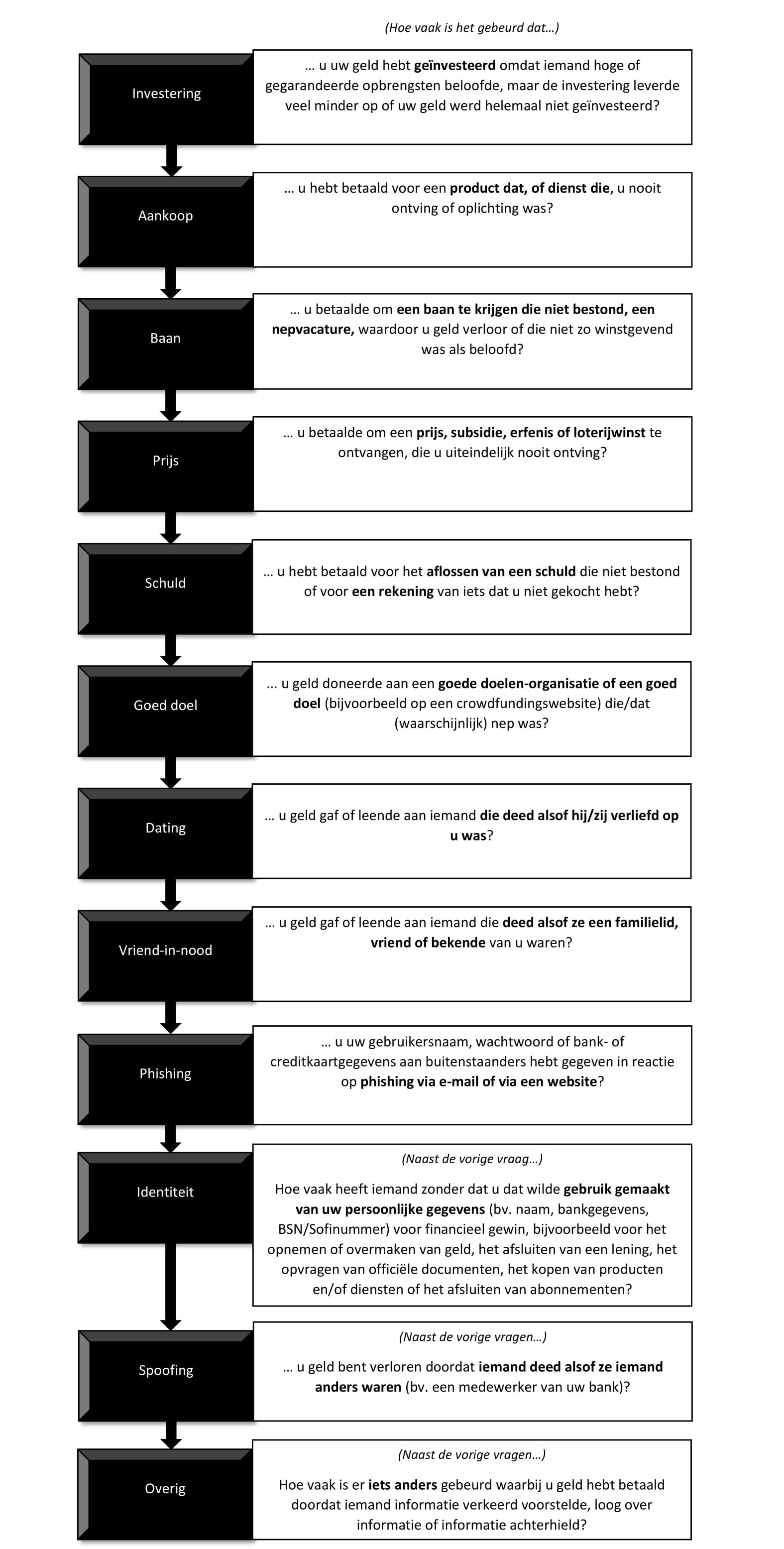
Figuur 2.1: Fraudetaxonomie
2.2.2 Structuur en gemeten variabelen
De vragenlijst bestond uit verschillende delen, hieronder samengevat. De gehele vragenlijst is publiekelijk beschikbaar (link).
2.2.2.1 Victimisatiescreening
Voor elke fraudecategorie in Figuur 2.1 gaven respondenten aan hoe vaak zij hiervan in het afgelopen jaar (1 januari t/m 31 december 2020) en in de afgelopen 5 jaar (2016 t/m 2020) slachtoffer zijn geworden. Ook gaven respondenten voor elke fraudecategorie aan of zij een mislukte fraudepoging hebben meegemaakt (ja/nee). Zo ja, ook of ze op een mislukte fraudepoging hebben gereageerd (ja/nee) (bij identiteitsfraude is dit niet bevraagd, omdat bij deze fraudevorm geen contact nodig is tussen de dader en het slachtoffer).
Respondenten werd vooraf aan de victimisatiescreening verteld dat zij het begrip ‘geld’ breed mochten opvatten, waarbij alles meetelt waarmee zij dingen zouden kunnen kopen of wat zij gemakkelijk zouden kunnen omzetten in iets waarmee ze dingen kunnen kopen (inclusief valuta, cryptovaluta, virtueel geld in videogames, aandelen, obligaties en oppotmiddelen). Bij slachtofferschap hoorden ook betalingen waartoe respondenten een opdracht hadden gedaan, maar die daarna toch gestopt werden (door bijvoorbeeld een bank of creditkaartmaatschappij).
2.2.2.2 Vervolgvragen bij elke fraudecategorie
Hierna volgden voor iedere fraudecategorie waarvan een respondent in 2020 slachtoffer was een aantal vervolgvragen. Dit bestond uit 1) vragen specifiek over de incidentcategorie (bijvoorbeeld bij investeringsfraude, ‘Wat voor investering was het?’) en 2) standaardvragen die bij elke incidentcategorie gesteld werden (bijvoorbeeld, hoeveel geld er betaald/verloren was).
Respondenten werd per fraudecategorie gevraagd om voor deze vragen te denken aan de slachtofferschapsgebeurtenis waarbij ze het meeste geld hadden betaald of verloren; als er meerdere gebeurtenissen met eenzelfde grootste bedrag waren, of als er geen geld betaald/verloren was, dan aan de gebeurtenis waarvan ze nog het meeste wisten.
2.2.2.3 Belangrijkste slachtofferschap en mislukte poging
Vervolgens werden verdiepende vragen gesteld over de belangrijkste slachtofferschapsgebeurtenis in 2020 (indien slachtoffer), alsmede de belangrijkste mislukte fraudepoging in 2020 (indien meegemaakt).
Respondenten werden bij deze beide sets vragen geïnstrueerd om te denken aan de belangrijkste gebeurtenis (indien er meerdere slachtofferschapsgebeurtenissen/meerdere mislukte fraudepogingen waren). Bij slachtofferschapsgebeurtenissen was dat de gebeurtenis waarbij het meeste geld was betaald/verloren; als er meerdere gebeurtenissen met eenzelfde grootste bedrag waren, of er geen geld betaald/verloren was, dan was dat de gebeurtenis waarvan respondenten nog het meeste wisten. Bij mislukte fraudepogingen was dat de gebeurtenis waarvan respondenten nog het meeste wisten.
2.2.2.4 Achtergrondvragen
Tenslotte vulden respondenten enkele achtergrondvragen in die risicofactoren maten: een dysfunctionele impulsiviteitsschaal (gebaseerd op Dickman (1990)) en een cyberveiligheidsschaal (gebaseerd op Domenie, Leukfeldt, Wilsem, Jansen, & Stol (2013) en CBS (2018)). Ook werd respondenten gevraagd voor elke fraudecategorie aan te geven of zij, voor het invullen van de vragenlijst en voor zij mogelijk zelf in aanraking kwamen met de fraudevorm, hiervan wel eens gehoord hadden (ja/nee).
2.3 Voorbewerking van de data
Voor de start van de analyse zijn alle door respondenten ingevulde antwoorden gecontroleerd.
9 respondenten zijn verwijderd vanwege onbetrouwbare antwoorden. 8 van hen vulden meermaals (hoge) slachtofferfrequenties in, waarna ze in vervolgvragen meermaals non-descriptieve antwoorden of ‘niet van toepassing’ noteerden. 1 van hen vulde onder meerdere fraudecategorieën steeds ‘aandelen btc’ in. Dit leidde tot een uiteindelijk steekproef van 2864 respondenten.
Daarna zijn alle antwoorden bij slachtofferschapsgebeurtenissen in elke categorie, de belangrijkste slachtofferschapsgebeurtenis en de belangrijkste mislukte fraudepoging gecontroleerd. Hierbij zijn de volgende principes gehanteerd:
• Als respondenten bij vervolgvragen over een bepaalde gebeurtenis ‘niet van toepassing,’ ‘verkeerd ingevuld’ of gerelateerde antwoorden invulden, leidde dit tot verwijdering van die gebeurtenis (en alle bijbehorende antwoorden);
• Als respondenten bij een slachtofferschapsgebeurtenis (anders dan in de fraudecategorieën phishing en id-fraude, waarbij niet per definitie een bedrag betaald of verloren moest zijn) een betaald/verloren bedrag van ‘0’ invulden, werd deze gebeurtenis verwijderd indien uit andere antwoorden ook niet bleek dat er een gebeurtenis heeft plaatsgevonden. Indien op basis van andere antwoorden wel kon worden vastgesteld dat er een gebeurtenis had plaatsgevonden, dan werd deze gebeurtenis hergecategoriseerd als een mislukte fraudepoging (indien als zodanig beschreven), of werden de bedragen als missend aangemerkt (indien beschreven als slachtofferschapsgebeurtenis, zonder genoemde bedragen) of gecorrigeerd naar de juiste bedragen (indien beschreven als slachtofferschapsgebeurtenis, met genoemde bedragen);
• Als respondenten onder een fraudecategorie iets antwoordden dat niet consistent was met de categoriedefinitie, werd gekeken of er een andere fraudecategorie was waaronder de gebeurtenis wel paste. Zo ja, dan werd de gebeurtenis als zodanig hergecategoriseerd (met prioriteit voor fraudecategorieën die eerder voorkomen in de fraudetaxonomie). Zo nee, dan werd de gebeurtenis onder de ‘overige’-categorie geplaatst.
• Als respondenten onder de identiteits-, spoofing- en overig-fraudecategorieën iets beschreven dat paste onder een voorgaande (specifiekere) fraudecategorie, werd de gebeurtenis als zodanig hergecategoriseerd. Deze categorieën dienden namelijk overige gebeurtenissen (naast voorgaande vragen) op te vangen.
• Bij hercategorisatie of verwijdering op basis van een slachtofferschapsgebeurtenis zijn alle slachtofferschapsgetallen en de mislukte fraudepoging- plus mislukte fraudepoging-beantwoording-vragen uit de victimisatiescreening overgezet naar de nieuwe categorie (indien van toepassing), en op ‘0’ en ‘nee’ gezet in de oude categorie. Bij hercategorisatie of verwijdering op basis van een mislukte fraudepoging zijn enkel de mislukte fraudepoging- plus mislukte fraudepoging-beantwoording-vragen overgezet naar de nieuwe categorie (indien van toepassing), en op ‘nee’ gezet in de oude categorie. Waar vragen overeenkwamen tussen oude en nieuwe categorieën zijn deze overgeplaatst; onbeantwoorde vragen in nieuwe categorieën zijn als missend aangemerkt.
• Hercategoriseringen en verwijderingen zijn uitgevoerd in de volgorde die een zo groot mogelijk databehoud kon bereiken. Bijvoorbeeld: als voor een respondent een slachtofferschapsgebeurtenis in de spoofing-categorie moest worden overgeplaatst naar de vriend-in-nood-categorie, en de slachtofferschapsgebeurtenis die origineel was opgegeven in de vriend-in-nood-categorie moest worden verwijderd, dan vindt eerst de verwijdering plaats.
Dit leidde tot 133 verwijderde slachtofferschapsgebeurtenissen, 60 verwijderde mislukte fraudepogingen, 73 slachtofferschapsgebeurtenissen die zijn hergecategoriseerd in een andere fraudecategorie, 122 slachtofferschapsgebeurtenissen die zijn hergecategoriseerd als een mislukte fraudepoging (waarvan 67 ook in een andere fraudecategorie) en 135 mislukte fraudepogingen die zijn hergecategoriseerd in een andere fraudecategorie.
Daarnaast zijn nog enkele overige correcties uitgevoerd bij foutief geselecteerde antwoorden op losse doorvragen bij slachtofferschapsgebeurtenissen van 8 respondenten, niet kloppende betaalde/verloren bedragen van 10 respondenten en onwaarschijnlijk hoge slachtofferfrequenties van 4 respondenten. 7 respondenten beschreven mislukte fraudepogingen in meerdere fraudecategorieën onder één mislukte fraudepoging; de mislukte fraudepoging-vraag is voor die beschreven fraudecategorieën op ‘ja’ gezet. 4 respondenten beschreven onder een mislukte fraudepoging een slachtofferschapsgebeurtenis; die mislukte fraudepogingen zijn hergecategoriseerd als slachtofferschapsgebeurtenissen.
Alle uitgevoerde voorbewerkingen, inclusief de specifieke redenen daartoe, zijn gedocumenteerd in de publiekelijk beschikbare analysecode (link).
2.4 Analyse
De analyse is uitgevoerd in R (R Core Team, 2021). De analysecode is publiekelijk beschikbaar (link).
De gehele analyse is gedaan met weging (beschreven onder 2.1). Alle gepresenteerde statistieken zijn dus statistieken gewogen naar de Nederlandse bevolking. Uitzondering hierop zijn de getoonde absolute respondentenaantallen en de regressieanalyses; deze zijn ongewogen.