- Computing with disordered dopant networks
Computing with disordered dopant networks
Researchers: Tao Chen, Bram van de Ven
Funding: The Dutch Research Council (NWO), University of Twente


 Dopant networks are formed in crystalline silicon doped with impurities like boron or arsenic atoms. They are capable of performing canonical machine learning tasks. Doped silicon is the backbone of the modern integrated circuit industry and also a favorable substrate for electromechanical systems. In conventional electronic devices, the charge carriers are thermally ionized from the dopant atoms to the energy bands of silicon, leading to band conduction. When the thermal energy is insufficient to ionize the charge carriers, the dopant atoms can have either zero or one carrier localized in their potential wells. The dopant atoms couple to each other via Coulomb interactions, forming a virtual network that can process information in a brain-like manner [T. Chen et al., Nature 577, pp. 341–345 (2020)].
Dopant networks are formed in crystalline silicon doped with impurities like boron or arsenic atoms. They are capable of performing canonical machine learning tasks. Doped silicon is the backbone of the modern integrated circuit industry and also a favorable substrate for electromechanical systems. In conventional electronic devices, the charge carriers are thermally ionized from the dopant atoms to the energy bands of silicon, leading to band conduction. When the thermal energy is insufficient to ionize the charge carriers, the dopant atoms can have either zero or one carrier localized in their potential wells. The dopant atoms couple to each other via Coulomb interactions, forming a virtual network that can process information in a brain-like manner [T. Chen et al., Nature 577, pp. 341–345 (2020)].
The dopant network can potentially carry out operations with ultra-high energy efficiency. To train the network for a certain task, we use the concept of ‘Material Learning’. We can train the dopant network by tuning its potential landscape. For instance, from a dopant network connected to eight electrodes, two electrodes can be used as inputs which receive data encoded as voltages, and one electrode can be used as output at which current is measured. The other five electrodes act as controls, and the control voltages can be optimized using a genetic algorithm [S.K. Bose, C.P. Lawrence et al., Nature Nanotechnol. 10, pp. 1048-1052 (2015)]. This two-input-one-output configuration can perform arbitrary Boolean logic functions, demonstrating universality and ability to solve linearly inseparable problems (XOR). We have also shown that, with a four-input-one-output configuration, the dopant network can filter 2x2 pixel features, which can be applied in handwritten digits classification with over 96% accuracy.
We envision scaled up systems based on material computing, some materials suitable for nonlinear operations such as our dopant networks, and some suitable for memory and linear operations such as memristors. These materials can be programed with corresponding learning methods, which we refer to as material learning. The material-based systems can reach over 100 TOP/s/W (tera operations per second per Walt). By scaling up the network, the material learning approach offers an energy-efficient and compact hardware platform for future artificial intelligence.
Publications
Classification with a disordered dopantatom network in silicon
Tao Chen, Jeroen van Gelder, Bram van de Ven, Sergey V. Amitonov, Bram de Wilde, Hans-Christian Ruiz Euler, Hajo Broersma, Peter A. Bobbert, Floris A. Zwanenburg & Wilfred G. van der Wiel Nature 577, pp. 341–345 (2020)
- Nanomaterial Networks for Artificial Intelligence in the Automotive Industry: NANO(AI)2
NANOMATERIAL NETWORKS FOR ARTIFICIAL INTELLIGENCE IN THE AUTOMOTIVE INDUSTRY: NANO(AI)2
Researcher: Unai Alegre-Ibarra
Funding: The Dutch Research Council (NWO), Toyota Motor Europe, Simbeyond



Autonomous and computer-assisted driving are disruptively changing the automotive industry. The idea is to have vehicles with little or no human input, which are able to sense their environment, and safely navigate through it. Additionally, advanced driver assistance systems (ADAS), also provide support for the driver while parking or driving. The driver can receive assistance which is partially, highly or fully automated.
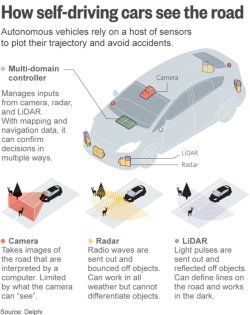
[7] A representation of how self driving cars perceive the surrounding environment. Source:Delphi, https://www.flickr.com/photos/101677470@N02/26771977022, 2016, [Online; accessed 10-August-2020].
In order to perceive their surrounding environment, vehicles are equipped with vision (cameras, LiDAR, radar), sound (microphones) and location (GPS/IMU) sensors [1]. The vehicle needs to position itself, not only on the map, but also needs to have some scene understanding, as well as a driving policy, to plan actions according to the different situations that might occur. Autonomous driving needs to actively recognize and classify relevant traffic events. For instance, the vehicle might require to understand and process traffic signs and lanes, as well as surrounding objects/people/obstacles, their expected behavior when next to them (such as yielding to an ambulance, or driving more carefully when the pedestrians are children), as well as their expected behavior around the autonomous vehicle (if they are going to stay still, move, yield, etc.) [2]. In addition, they need to process all this information while making the right driving decision in real-time, which requires considerable on-board intelligence.

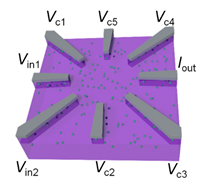
[8] Sketch of a DNPU with eight electrodes [4], where e_out is the readout electrode and the others can be either input or control electrodes, e.g. e1,2 and e0,3-6, respectively. To implement a classifier, voltages are applied to the input electrodes representing the features of the data, e.g. 0 and 1. Applying a learned voltage configuration to the control electrodes implements the classifier, e.g. XOR, as an output current representing the classes 0 and 1. Original source from: [5] and [4].
Artificial intelligence (AI) is widely considered crucial for optimally implementing this technology. Automotive giants such as Tesla and Google are spending millions of dollars on research to make autonomous cars a commercial reality. Recently, Ford Motor Company made an investment of one billion dollars in Argo AI, a new AI company to bring forth a virtual driver system in the future, possibly by 2021 [3]. A successful branch of Artificial Intelligence is that of neural-networks, which have proven to be successful in surpassing human performance on different specific tasks, such as playing the GO game [4]. The success of neural-networks, and in particular that of deep neural networks (DNNs), comes with an exponential increase in the number of parameters and operations, which brings along high energy costs, high latency, and massive hardware infrastructure. This computational demand coincides with the slowdown of Moore’s law, highlighting the need to search for other computational solutions beyond cramming more transistors in the same circuit area. There is a broad spectrum of research on hardware acceleration solutions for obtaining state of the art performance in DNNs while reducing associated costs.
The aim of the project NANO(AI)2 is to develop low-power, reconfigurable, nano-electronic devices in such a way that they can be applicable for reducing computational costs in tasks related to autonomous driving, in the automotive industry. Our systems consist of bottom-up assembled nano-scale material networks integrated with conventional top-down CMOS electronics. The project is a close collaboration between physicists, electrical engineers and computer scientists at BRAINS and the four users, and is based on the recent breakthrough results obtained [5]. We use the concept of a Dopant Network Processing Unit (DNPU) [6], a lightly doped (n- or p-type) semiconductor with a nano-scale active region contacted by several electrodes. Different materials can be used as dopant or host, and the number of electrodes can vary. Some of the electrodes, called activation electrodes, receive a voltage input, producing a current on a selected output electrode. The dopants in the active region form an atomic-scale network through which the electrons can hop from one electrode to another. This physical process results in an output current at the readout which depends non-linearly on the voltages applied at the activation electrodes. By tuning the voltages applied to some of the electrodes, the output current can be controlled as a function of the voltages at the remaining electrodes. This tunability can be exploited to solve various linearly non-separable classification tasks, which are equivalent to tasks that a small artificial neural network can solve.
We are currently exploring the scalability of DNPUs, and its applicability to different tasks related to autonomous driving:
- Static task and static feature: Classifying a static object like a road sign while standing still, e.g., at a traffic light
- Dynamic task and static feature: Classifying a static object while driving
- Static task and dynamic feature: Classifying a moving object while standing still
- Dynamic task and dynamic feature Classifying a moving object while driving
References
[1] Lex Friedman, 6.S094: Deep Learning for Self-Driving Cars," https://selfdrivingcars.mit.edu/, 2018, [Online; accessed 7-August-2020].
[2] Hodges, C., An, S., Rahmani, H., & Bennamoun, M. (2019). Deep Learning for Driverless Vehicles. In Handbook of Deep Learning Applications (pp. 83-99). Springer, Cham.
[3] S.K. Bose, C.P. Lawrence, Z. Liu, K.S. Makarenko, R.M.J. van Damme, H.J. Broersma and W.G. van der Wiel, Evolution of a Designless Nanoparticle Network into Reconfigurable Boolean Logic, Nature Nanotechnology 10, 1048 (2015).
[4] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., ... & Dieleman, S. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
[5] Chen, T., van Gelder, J., van de Ven, B., Amitonov, S. V., de Wilde, B., Euler, H. C. R., ... & van der Wiel, W. G. (2020). Classification with a disordered dopant-atom network in silicon. Nature, 577(7790), 341-345.
[6] Ruiz-Euler, H. C., Alegre-Ibarra, U., van de Ven, B., Broersma, H., Bobbert, P. A., & van der Wiel, W. G. (2020). Dopant Network Processing Units: Towards Efficient Neural-network Emulators with High-capacity Nanoelectronic Nodes. arXiv preprint arXiv:2007.12371.
- Dopant Network Processing Units (DNPUs)
Research Summary DNPU networks:
The last decade has seen an explosion in artificial intelligence (AI) driven mainly by the success of deep neural networks (DNN) in many areas such as computer vision, natural language processing and robotics. Inspired by the biological neural networks in the brain, DNN are complex information processing systems composed of many neurons, or ‘units’, connected with each other in a network. DNN can be trained by changing their connections, or parameters, to solve specific tasks, like classifying objects in images or summarize texts and answer questions. State-of-the-art systems have human-like or even super-human performance in specific tasks. One example is OpenAI’s GPT-3, which is a language model able to generate text that human evaluators have difficulty distinguishing from text written by humans. However, the impressive performance of the GPT-3 comes at the cost of 175 billion parameters. This massive number of parameters requires large computing infrastructures, which cannot be deployed in technologies where energy consumption and space are limited, like smart phones, robots, or autonomous vehicles.
One could think of waiting some time for computers to become smaller and more powerful and energy efficient, a trend that we have being observing for decades, but the miniaturization and efficiency of computers is suffering a slow-down due to physical restrictions in the design of the basic elements of computers, the transistors. If we want to overcome the explosion in computational demands that modern AI is posing, we must develop new hardware. At BRAINS, we investigate novel approaches to solve these demands and develop hardware that emulates the computational abilities of neural networks.
Figure 1 The first DNPU network with a 2-2-1 architecture. We have implemented a small DNPU network to increase the range of tasks that our systems can solve. The architecture is implemented ‘virtually’, meaning that we use a single device to evaluate sequentially each of the nodes to implement the DNPU network. This is the first demonstration of the potential scalability of DNPUs to hardware neural network emulators.
Recently, BRAINS developed a nanoelectronic device [1] capable of solving classification problems that usually require neural networks with several neurons [2]. These so-called Dopant Network Processing Units (DNPUs) are energy efficient, have a very high theoretical throughput and can be used as units in hardware implementations of neural networks. We demonstrated [2] that by emulating a neural network using a DNPU (see Fig. 1) we significantly improve the classification accuracy from 77% to 94% vis-à-vis single DNPU implementations on a task with binary concentric classes (see Fig. 2).
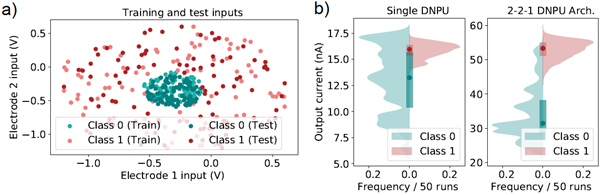
Figure 2 Ring classification task; a) data used for training and testing the DNPU systems. The data consist of binary concentric classes on a plane where one class is a cluster (green) and another class is a concentric ring (red). The task consists of assigning data points to the corresponding classes 0 (low) or 1 (high) respectively; b) output distribution of a single DNPU and a 2-2-1 DNPU-network on the test data. The output is divided by classes. We can see the strong overlap of the classes in the single DNPU output, meaning this system fails to accurately classify the data (23% error rate). On the contrary, with a small network of 5 DNPUs we can decrease the error rate to 6% by significantly separating the outputs for each class.
These neural network emulators can potentially reduce the number of parameters and operations needed to process data, and consequently, reduce the energy consumption in AI related tasks. We have shown in simulation, that a single DNPU-layer network with only 10 DNPUs achieves commendable 96% classification accuracy on a typical benchmark task where handwritten single digits must be classified into one of the classes from 0 to 9 (see Fig. 3).
We are investigating different forms to upscale this technology to large hardware neural network emulators that are flexible, energy efficient and have high throughput.
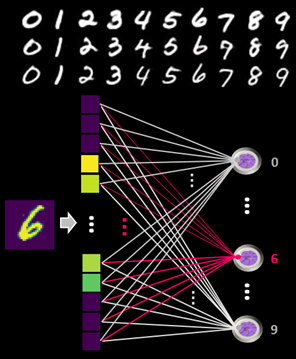
Figure 3 Single DNPU-layer classifier. MNIST is a benchmark dataset with handwritten single digit (0-9) images of 28x28 pixels. The task is to recognise the digit in the image. We simulated a classifier with only 10 nodes, one for each digit, and obtained an accuracy of 96%. This architecture is motivated by the integration of DNPUs with memristor crossbar arrays, a technology that can implement matrix-vector multiplication efficiently.
[1] Chen, T. et al. Classification with a disordered dopant-atom network in silicon. Nature 577, 341–345 (2020). https://doi.org/10.1038/s41586-019-1901-0
[2] Ruiz Euler, Hans-Christian et al. "Dopant Network Processing Units: Towards Efficient Neural-network Emulators with High-capacity Nanoelectronic Nodes." arXiv e-prints (2020): arXiv-2007.