A Step towards Federated Learning
CONTEXT
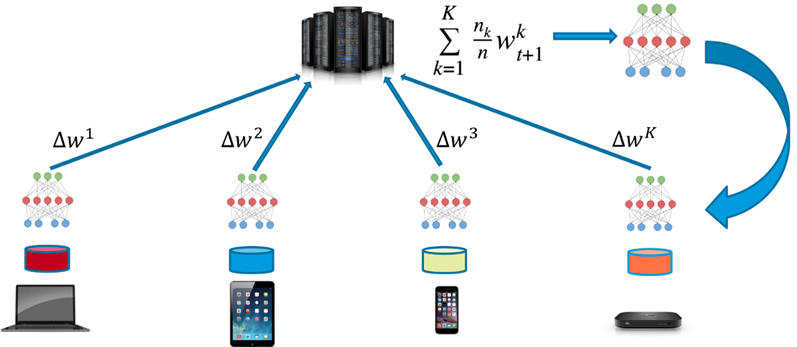
With the ever-growing concerns about data privacy and the rapid increase in data volume, distributed machine learning seems to be the best approach to fulfilling these demands. Federated Learning is a type of distributed machine learning that can (i) not only strongly preserve data privacy, e.g., identity information, company profiles, and sale history by closely keeping data in place all the time, (ii) but also exchange much less lightweight information than the raw data as centralized one did among involved parties, e.g., different organizations, different devices for weight aggregation. However, because of variations in different parties, the base model that is shared by these parties is heavily contaminated with information conflicts, which is termed as none-Independently and Identically distributed (none-IID) data. This is notoriously a primary impediment to the convergence of the base model on different parties, not to mention another aspect, communication efficiency.
Task
In this work, students are expected to briefly review state-of-the-art work in the scope of the non-IID problem only and then carefully analyze the strengths and weaknesses of respective ones. From that, they are strongly encouraged to come up with completely new ideas that can clearly contribute to the regularization of non-IID data problems.
YOU WILL GET
- Profound experience in related fields, such as deep learning models, and distributed learning balancing.
- A publication at top-tier AI venues if the work is qualified.
REQUIREMENTS
- Strong background in Machine Learning and Deep Learning.
- At least familiar with one of the AI frameworks, such as Tensorflow, and Pytorch.
- Having hands-on experience in basic Deep Learning projects.
- A good comprehension of related papers.
Contact:
Minh Son Nguyen, m.s.nguyen@utwente.nl