Language-guided Audio-Visual Source Separation
CONTEXT
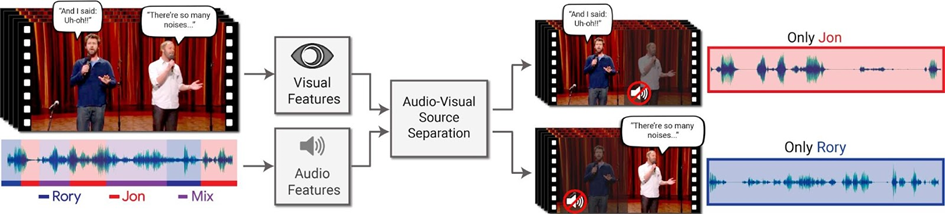
The world is generally surrounded by audiovisual things, particularly multiple audio sources interleave with one another. For example, at the theatre, an orchestra of a large group of people led by a conductor performs a soundtrack on a variety of instruments, which thus create an enjoyable combination of complementary melodies for the audience. Humans have an innate ability to discern the melody of a single sound source from various instruments. In fact, this ability can enable a broad spectrum of essential but very useful tasks that would serve and accelerate human lives better. Specifically, its applications can be seen more nowadays, such as noise cancellation, speaker separation, and voice enhancement. Along with the proliferation of digital data, there are three typical modalities, namely visual, audio, and textual information that can help to augment the performance of effectively separating multiple sources. These things have been put forward further with the emergence of deep learning techniques.
Task
In this work, students are expected to review state-of-the-art work around this research briefly and then carefully analyze the strengths and weaknesses of respective ones. From that, they are positively encouraged to propose their own novel solutions that can significantly improve fidelity and efficiency in sound source separation.
YOU WILL GET
- Profound experience in related fields, such as deep learning models, and multi-modal processing.
- A publication at top-tier AI venues if the work is qualified.
REQUIREMENTS
- Strong background in Machine Learning and Deep Learning.
- At least familiar with one of the AI frameworks, such as Tensorflow, and Pytorch.
- Having hands-on experience in basic Deep Learning projects.
- A good comprehension of related papers.
Contact:
Minh Son Nguyen, m.s.nguyen@utwente.nl