Evaluation of dataset condensation methods in (biodiversity) datasets
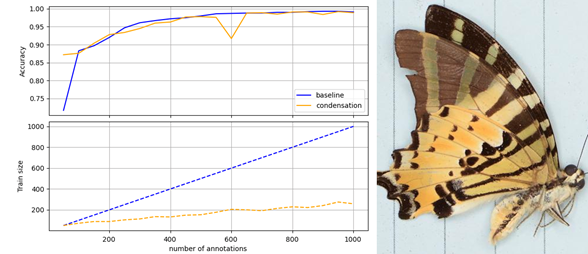
Pilot experiment that shows that condensation reduces the train set size (and thus GPU time and energy costs) while maintaining classification performance. (left). Example of type of biodiversity images used in the research (right).
Problem Statement:
Intel is developing solutions for interactively creating AI models and deploying them efficiently in practice. This assignment can be fulfilled as an internship at Intel.
The incremental human-in-the-learning loop consists of several steps: annotation of an “active set”, model training, model evaluation and a new sampling of the active set. The last step is the active learning step and aims at finding unlabelled interesting samples to be annotated by the user. What is interesting can be defined in many ways including uncertainty, outliers, distance to known samples, etc. After interesting images have been annotated and added to the labelled dataset, they will become less interesting because they are now part of the training set and are more likely to be correctly recognized. The labelled set will grow and will increase training times.
This internship is concerned with reducing the size of the training set to speed up training. The goal is to reduce the size of the training set with similar or better performance measures. The general term for reducing the size of the training set is condensation. Successful outcomes of these experiments could lead to a recommendation to include condensation as an integral part of the incremental learning loop to reduce GPU time and/or improve performance. Reducing GPU times saves costs but also energy use.
Methods to perform condensation can be the same methods as in active learning but now applied to the training set instead of the unlabelled set. The trainee is also encouraged to come up with new methods for finding interesting samples, possibly ones which are geared towards condensation specifically, for example class balancing (which cannot be done with an unlabelled set). Examples of other methods are Shapley values and core-sets.
In this internship you will compare different approaches to condensation on several datasets, including complex biodiversity datasets. Biodiversity datasets are characterized by having many fine-grained classes, a hierarchical class structure, a large imbalance in numbers of samples per class and partially overlapping classes. These challenging conditions make biodiversity datasets a good test case for other real-world applications. While the focus is on implementing and evaluating existing methods there is room for developing your own approaches. A successful internship could result in a scientific publication.
Task:
This internship assumes
· You are studying for a MSc in computer science, data science, computational biology, cognitive science, artificial intelligence, or related fields
· Experience with training deep learning models using one of the common frameworks (PyTorch, Tensorflow)
· Good Python skills
· A good understanding of statistical analysis and testing
Position in Intel
You will be part of the incremental learning and data exploration research group. There will be daily and weekly meetings with your supervisors. As teams are distributed part of these meetings will be remote.
Intel has offices at Groningen, Netherlands (Interactive AI), but you are welcome to work from other sites depending on the actual COVID situation.
Contact:
- Daily supervisor: Laurens Hogeweg. Please contact laurens.hogeweg@intel.com for more information.
- UT supervisor: Jacob Kamminga. j.w.kamminga@utwente.nl